哈希函数
散列函数(英语:Hash function)又称散列算法、哈希函数,是一种从任何一种数据中创建小的数字“指纹”的方法。散列函数把消息或数据压缩成摘要,使得数据量变小,将数据的格式固定下来。该函数将数据打乱混合,重新创建一个叫做散列值(hash values,hash codes,hash sums,或hashes)的指纹。散列值通常用一个短的随机字母和数字组成的字符串来代表。
- 输入定义上是无穷的但是实际使用通常会设置阈值,如 MD5 接受0-2^64-1的范围。
- 输出的长度是固定的
- 对于计算机的计算能力是不可逆的
- 一个输入对应一个输出(也存在 hash 碰撞的问题)
- 哈希函数产生的映射应当保持均匀,即不要使得映射结果堆积在小区间的某一块区域。(即保证离散型和均匀性)
相关题目
一个包含40亿条数据的文件,每个数据为无符号的32位整数,要求在 1G 内存以内完成找到出现次数前百最多的数据
思路:将文件中的每条数据进行 hash 后再对 n 取模,40亿条数据的结果应该都是均匀分布在0 - (n-1)范围上的,将结果相同的数据放入同一文件,对每个文件分别进行词频统计,得出 n 个数,合并后再取出最多的数据即可
下面提供了一种思路,但是内存占用应该是比较大的,因为开启了多个协程且使用管道进行通信,想要降低内存可以改为串行处理
type KV struct {
Key string
Value int
}
func Handle(path string, n int, hFunc HFunc) *KV {
f, err := os.Open(path)
if err != nil {
log.Fatalln(err)
}
defer f.Close()
channels := make(map[int]chan string)
for i := 0; i < n; i++ {
num := i
ch := make(chan string)
go writeFile(fmt.Sprintf("%d", num), ch)
channels[num] = ch
}
scanner := bufio.NewScanner(f)
for scanner.Scan() {
num := hFunc(scanner.Text()) % n
ch := channels[num]
ch <- scanner.Text()
}
for _, v := range channels {
close(v)
}
resCh := make(chan *KV, n)
for i := 0; i < n; i++ {
num := i
go readFile(fmt.Sprintf("%d", num), resCh)
}
results := make([]*KV, n)
for i := 0; i < n; i++ {
v := <-resCh
results[i] = v
}
sort.Slice(results, func(i, j int) bool {
return results[i].Value > results[j].Value
})
return results[0]
}
func writeFile(path string, ch <-chan string) {
f, err := os.OpenFile(path, os.O_WRONLY|os.O_CREATE, 0755)
if err != nil {
return
}
defer f.Close()
for v := range ch {
fmt.Fprintln(f, v)
}
}
func readFile(path string, result chan<- *KV) {
f, err := os.Open(path)
if err != nil {
return
}
scanner := bufio.NewScanner(f)
res := make(map[string]int)
for scanner.Scan() {
res[scanner.Text()] += 1
}
maxKey := ""
max := 0
for k, v := range res {
if v > max {
maxKey = k
max = v
}
}
result <- &KV{Key: maxKey, Value: max}
}
哈希表
经典 hash map 设计是这样的:一开始创建 n 个存储桶,对每个放入的 key 做 hash 操作后对 n 取模得到 a,将此数据放入 a 桶中。因为 hash 函数的均匀性,当某一个桶的数据数量达到某一阈值时,可以看做其他桶的数量也逼近此阈值,触发扩容。举个扩容的例子:新建原来存储桶的倍数个存储桶,将原来存储的数据重新进行 hash,对 2*n 取模的运算后放入对应桶中。
对 hash map 的读操作与写操作类似,对 key 进行 hash,取模的操作后找到对应桶,再根据 key 具体值找到对应的 value
只需要保证每个桶的数据量维持在一个较小的阈值,每次对数据的操作都是较小的常数时间的,扩容代价可能较大,但是不同语言都有自己的优化机制,我们在对hash map 操作的时候时间复杂度都可以看做是 O(1) 的
相关题目
设计 RandomPool 结构
【题目】 设计一种结构,在该结构中有如下三个功能: insert(key): 将某个 key 加入到该结构,做到不重复加入 delete(key): 将原本在结构中的某个key移除 getRandom(): 等概率随机返回结构中的任何一个key。
【要求】 Insert、delete和getRandom方法的时间复杂度都是O(1)
思路:维护两张表,一张 key-value,一张 value-key。insert 函数每次将 insert 前的 hash map 中数据个数作为 value,数据本身作为 key对两张表都进行 insert 操作。getRandom 函数就随机生成一个 0 - len(map) 的数作为 value 在表中查询对应的 key 返回即可。delete 操作删除先将两张 map 中最后一条记录的 value 变为为要删除的 key 的 value,然后进行删除操作
type RandomPool struct {
keyValue map[string]int
valueKey map[int]string
}
func NewRandomPool() *RandomPool {
return &RandomPool{keyValue: make(map[string]int), valueKey: make(map[int]string)}
}
func (r *RandomPool) Insert(key string) {
value := len(r.valueKey)
r.keyValue[key] = value
r.valueKey[value] = key
}
func (r *RandomPool) GetRandom() string {
random := rand.Intn(len(r.valueKey))
return r.valueKey[random]
}
func (r *RandomPool) Delete(key string) {
if _, ok := r.keyValue[key]; !ok {
return
}
size := len(r.valueKey)
index := r.keyValue[key]
last := r.valueKey[size]
r.valueKey[index] = r.valueKey[size]
r.keyValue[last] = index
delete(r.valueKey, size)
delete(r.keyValue, key)
}
布隆过滤器
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
原理
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
特性
- 一个元素如果判断结果为存在的时候元素不一定存在,但是判断结果为不存在的时候则一定不存在。
- 布隆过滤器可以添加元素,但是不能删除元素。因为删掉元素会导致误判率增加。
适用场景
如网页 URL 去重、垃圾邮件识别、大集合中重复元素的判断和缓存穿透等问题
布隆过滤器的典型应用有:
- 数据库防止穿库。 Google Bigtable,HBase 和 Cassandra 以及 Postgresql 使用 BloomFilter 来减少不存在的行或列的磁盘查找。避免代价高昂的磁盘查找会大大提高数据库查询操作的性能。
- 业务场景中判断用户是否阅读过某视频或文章,比如抖音或头条,当然会导致一定的误判,但不会让用户看到重复的内容。
- 缓存宕机、缓存击穿场景,一般判断用户是否在缓存中,如果在则直接返回结果,不在则查询db,如果来一波冷数据,会导致缓存大量击穿,造成雪崩效应,这时候可以用布隆过滤器当缓存的索引,只有在布隆过滤器中,才去查询缓存,如果没查询到,则穿透到db。如果不在布隆器中,则直接返回。
- WEB拦截器,如果相同请求则拦截,防止重复被攻击。用户第一次请求,将请求参数放入布隆过滤器中,当第二次请求时,先判断请求参数是否被布隆过滤器命中。可以提高缓存命中率。Squid 网页代理缓存服务器在 cache digests 中就使用了布隆过滤器。Google Chrome浏览器使用了布隆过滤器加速安全浏览服务
- Venti 文档存储系统也采用布隆过滤器来检测先前存储的数据。
- SPIN 模型检测器也使用布隆过滤器在大规模验证问题时跟踪可达状态空间。
实现
布隆过滤器的存储结构是 bitmap
相关 API:
- 新增:将元素经过 k 个 hash 函数计算后的得到 k 个值,将这些值在 bitmap 中对应的位设置为1
- 查询:将元素经过 k 个 hash 函数计算后的得到 k 个值,如果这些值在 bitmap 中对应位置全为1,则极大可能已经存在了,有一位为0则一定不存在
在实现具体 API 前我们要先确定 bitmap 的大小和 k 的值,实际上这两个值并不都是越大越好,在样本数量和 hash 函数个数确定的情况下,bitmap 的大小与 失误率 p 大致为一个反比例函数;在样本数量和 bitmap 大小确定的时候,hash 函数的个数和失误率的关系就像对勾函数的上支。这两个值的选择要看具体的使用场景。
计算公式:计算结果均向上取整,n 为样本量,p 为预期失误率
bitmap 大小:m = - (n*lnp)/(ln2)^2
hash 函数个数:k = ln2 * m/n
p真 = (1 - e^-((n*k真)/m真))^k真
type HFunc func(str string) int
type BloomFilter struct {
bitmap []byte
hashFunc []HFunc
}
func NewBloomFilter(m int, hashFunctions ...HFunc) *BloomFilter {
return &BloomFilter{
bitmap: make([]byte, m/8+1),
hashFunc: hashFunctions,
}
}
func (b *BloomFilter) Add(str string) {
bits := b.hash(str)
for _, v := range bits {
b.setBit(v)
}
}
func (b *BloomFilter) Query(str string) bool {
bits := b.hash(str)
for _, v := range bits {
if b.getBit(v) == 0 {
return false
}
}
return true
}
func (b *BloomFilter) hash(str string) []int {
result := make([]int, 0, len(b.hashFunc))
for _, v := range b.hashFunc {
result = append(result, v(str))
}
return result
}
func (b *BloomFilter) getBit(offset int) int {
blockIndex := offset / 8
bitIndex := offset % 8
return b.bitmap[blockIndex] >> bitIndex & 1
}
func (b *BloomFilter) setBit(offset int) {
blockIndex := offset / 8
bitIndex := offset % 8
b.bitmap[blockIndex] = (1 << bitIndex) | b.bitmap[blockIndex]
}
一致性哈希
现在我们需要搭建一个分布式的数据存储服务器。我们需要考虑两个问题:第一个问题本质是数据分区,第二个是数据复制。
对于一般的 hash 算法,解决方案是这样的:选取数据的某部分进行 hash 运算,再与服务器数量取模得到对应的服务器。但是这样处理的话面临一个很大的问题就是当服务器数量改变时,数据的迁移与备份,成本极高
对于这个的问题的解决我们可以使用一致性 hash 算法
大概思想
一致性 hash 算法可以用于数据和服务器节点,并确保在添加或删除服务器节点时只移动一小部分数据。
将 hash 值域想象一个顺时针递增的环,对不同服务器信息进行 hash 运算结果(token)后放在环上,然后再每次处理数据的时候也对数据进行 hash 运算后打到环上,请求环上顺时针最近的服务器,每一台服务器处理的数据范围为 (上一个token+1)- > token
如何实现找到顺时针最近的服务器:对服务器计算得出的 token 值进行一个排序,将数据处理后得到的 hash 值在服务器 hash 值排序结果里面做二分查找,找到大于等于数据 hash 值的最左位置就是数据应该访问的服务器
在使用一致性 hash 算法的时候要想实现数据迁移的成本比一般 hash 算法低得多
- 新增服务器:在顺时针方向的下一台服务器的其原数据处理范围内被划分出来的属于新增服务器数据处理范围迁移到新增服务器即可
- 移除服务器:将将要移除的服务器的所有数据迁移到顺时针方向的下一台服务器
但是一致性 hash 算法也有可能会导致数据和负载分布的不均匀,对于这个问题,使用虚拟节点技术解决
虚拟节点
在上面的解决方案中,为每一台服务器分配单个 token,也就是给一个服务器节点分配一个相对较大的数据范围。这是一种静态范围划分,需要根据给定的节点数量计算出对应的数据范围。
在这个方案中添加或者删除节点时,如果我们希望各个服务器节点能够保持数据平衡和负载均衡,需要做大量的数据移动的工作。主要存在以下问题:
- 增加或删除节点:将导致重新计算数据范围,给集群带来巨大的管理开销;
- 热点数据问题:由于每个节点都被分配了一个很大的范围,如果数据分布不均匀,一些节点可能会成为热点节点。
虚拟节点的核心就是:将原本很大的数据范围划分为很多个较小的数据范围,然后将数据范围分发给不同的服务器,这些较小的数据范围被称为虚拟节点,对于每一台服务器,管理多个小的数据范围。
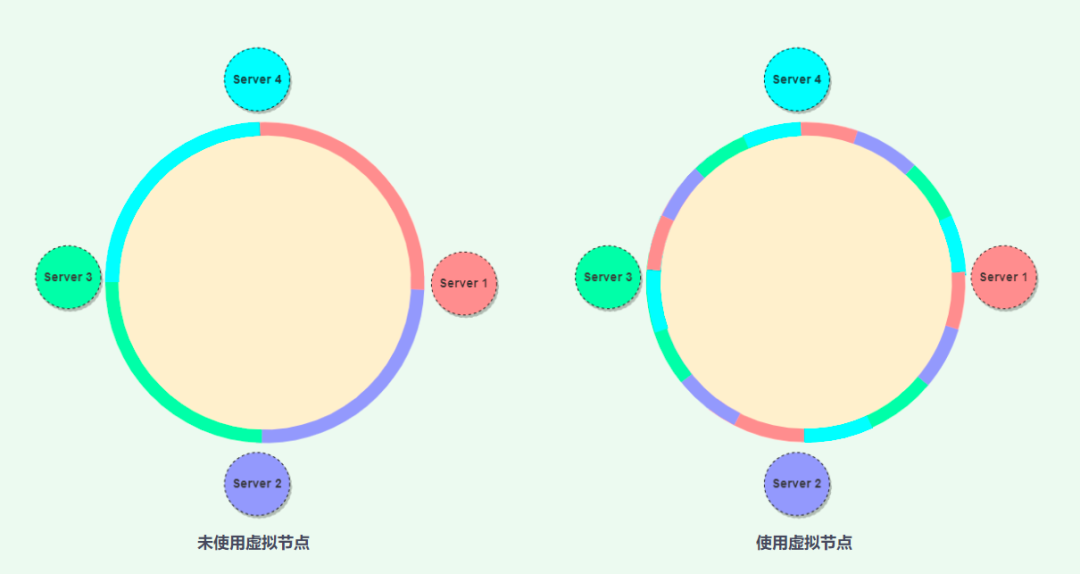
引入了虚拟节点的概念后对数据备份也可以有更好的优化:假设每台机器的数据需要备份3份,将每个数据计算出 hash 值后找到协调节点,此节点备份后再由顺时针的两个后续节点备份,这样每台服务器都会被其他服务器协调备份数据
优点
- 由于虚拟节点将哈希范围划分为更小的子范围,可以帮助集群上的物理节点更均匀地分配负载,因此在添加或删除节点时能更快的重新平衡;
- 当添加新的服务器节点时,它会从现有的节点转移一些虚拟节点过来,以维护集群的平衡;
- 同样,当一个节点需要重建时,许多节点都会参与重建过程,而不是从固定数量的副本中获取数据。使用虚拟节点在服务器性能存在差异化时更容易管理;
- 我们可以将大量的虚拟节点分配给功能强大的服务器,而将数量较少的虚拟节点分配给功能较弱的服务器;
- 由于虚拟节点帮助为每个物理节点分配很多较小的范围,这也降低了出现热点问题的可能性。
实现
挖个坑以后有空写